消息队列RabbitMQ(三):PHP的使用示例
之前的文章已经介绍RabbitMQ以及安装,本文就介绍PHP使用RabbitMQ的示例。
安装PHP的RabbitMQ扩展
本文介绍AMQP 0-9-1,这是一个开放的、通用的协议消息,这里我们使用php-amqplib这个PHP扩展。更多PHPAMQP扩展见官网。
通过composer安装
composer require php-amqplib/php-amqplib -vvv
如果你还不知道composer,那就out了。:)
Publisher(生产者,消息发送方)
创建publisher.php文件,并引入composer自动加载文件
require_once __DIR__ . '/vendor/autoload.php';
use PhpAmqpLib\Connection\AMQPStreamConnection;
use PhpAmqpLib\Exchange\AMQPExchangeType;
use PhpAmqpLib\Message\AMQPMessage;
Connection(创建连接)
创建RabbitMQ连接以及channel通道,AQMP的命令都是通过通道发出去的。
$connection = new AMQPStreamConnection('localhost', 5672, 'guest', 'guest');
// 创建通道
$channel = $connection->channel();
Send(发送消息)
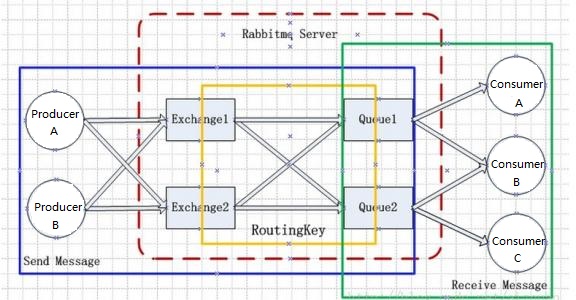
发消息前,我们必须声明一个队列为我们发送做准备;然后我们可以向队列发布消息:
/**
* 创建队列(Queue)
* name: hello // 队列名称
* passive: false // 如果设置true存在则返回OK,否则就报错。设置false存在返回OK,不存在则自动创建
* durable: true // 是否持久化,设置false是存放到内存中的,RabbitMQ重启后会丢失
* exclusive: false // 是否排他,指定该选项为true则队列只对当前连接有效,连接断开后自动删除
* auto_delete: false // 是否自动删除,当最后一个消费者断开连接之后队列是否自动被删除
*/
$channel->queue_declare('hello', false, false, false, false);
/**
* 创建交换机(Exchange)
* name: vckai_exchange// 交换机名称
* type: direct // 交换机类型,分别为direct/fanout/topic,参考另外文章的Exchange Type说明。
* passive: false // 如果设置true存在则返回OK,否则就报错。设置false存在返回OK,不存在则自动创建
* durable: false // 是否持久化,设置false是存放到内存中的,RabbitMQ重启后会丢失
* auto_delete: false // 是否自动删除,当最后一个消费者断开连接之后队列是否自动被删除
*/
$channel->exchange_declare('vckai_exchange', AMQPExchangeType::DIRECT, false, false, false);
// 绑定消息交换机和队列
$channel->queue_bind('hello', 'vckai_exchange');
/**
* 创建AMQP消息类型
* delivery_mode 消息是否持久化
* AMQPMessage::DELIVERY_MODE_NON_PERSISTENT 不持久化
* AMQPMessage::DELIVERY_MODE_PERSISTENT 持久化
*/
$msg = new AMQPMessage('Hello World!', ['delivery_mode' => AMQPMessage:: DELIVERY_MODE_NON_PERSISTENT]);
/**
* 发送消息
* msg: $msg // AMQP消息内容
* exchange: vckai_exchange // 交换机名称
* queue: hello // 队列名称
*/
$channel->basic_publish($msg, 'vckai_exchange', 'hello');
echo " [x] Sent 'Hello World!'\n";
这里需要特别说明的是关于Exchange、Queue和Message持久化的问题
如过将Queue的持久化标识durable设置为true,则代表是一个持久的队列,那么在服务重启之后,也会存在,因为服务会把持久化的Queue存放在硬盘上,当服务重启的时候,会重新加载之前被持久化的Queue。
队列是可以被持久化,但是里面的消息是否为持久化那还要看消息的持久化设置。也就是说,重启之前那个Queue里面还没有发出去的消息的话,重启之后那队列里面是不是还存在原来的消息,这个就要取决于发生着在发送消息时对消息的设置了。
上面阐述了队列的持久化和消息的持久化,如果不设置Exchange的持久化对消息的可靠性来说没有什么影响,但是同样如果Exchange不设置持久化,那么当Broker服务重启之后,Exchange将不复存在,那么既而发送方RabbitMQ Producer就无法正常发送消息。
Close(关闭链接)
$channel->close();
$connection->close();